
MobiMind
Collection
MobiMind Model Family of MobiAgent • 7 items • Updated
This is the Decider Model of MobiAgent with 7B parameters, as presented in the paper MobiAgent: A Systematic Framework for Customizable Mobile Agents, capable of high-level GUI interaction decision in GUI agent task execution.
With the rapid advancement of Vision-Language Models (VLMs), GUI-based mobile agents have emerged as a key development direction for intelligent mobile systems. However, existing agent models continue to face significant challenges in real-world task execution, particularly in terms of accuracy and efficiency. To address these limitations, we propose MobiAgent, a comprehensive mobile agent system comprising three core components: the MobiMind-series agent models, the AgentRR acceleration framework, and the MobiFlow benchmarking suite. Furthermore, recognizing that the capabilities of current mobile agents are still limited by the availability of high-quality data, we have developed an AI-assisted agile data collection pipeline that significantly reduces the cost of manual annotation. Compared to both general-purpose LLMs and specialized GUI agent models, MobiAgent achieves state-of-the-art performance in real-world mobile scenarios.
MobiAgent is a powerful mobile agent system including:
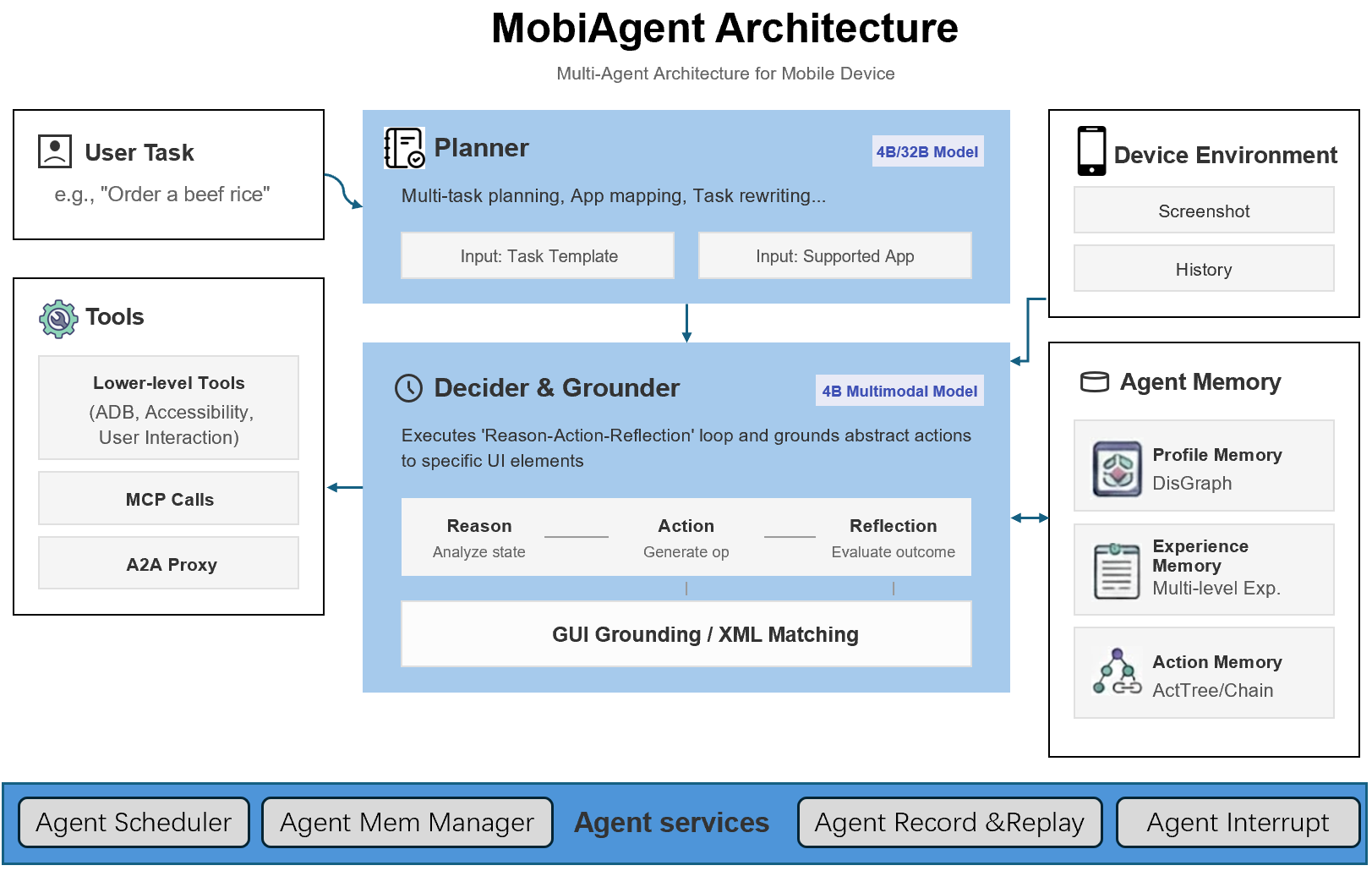
System Architecture:
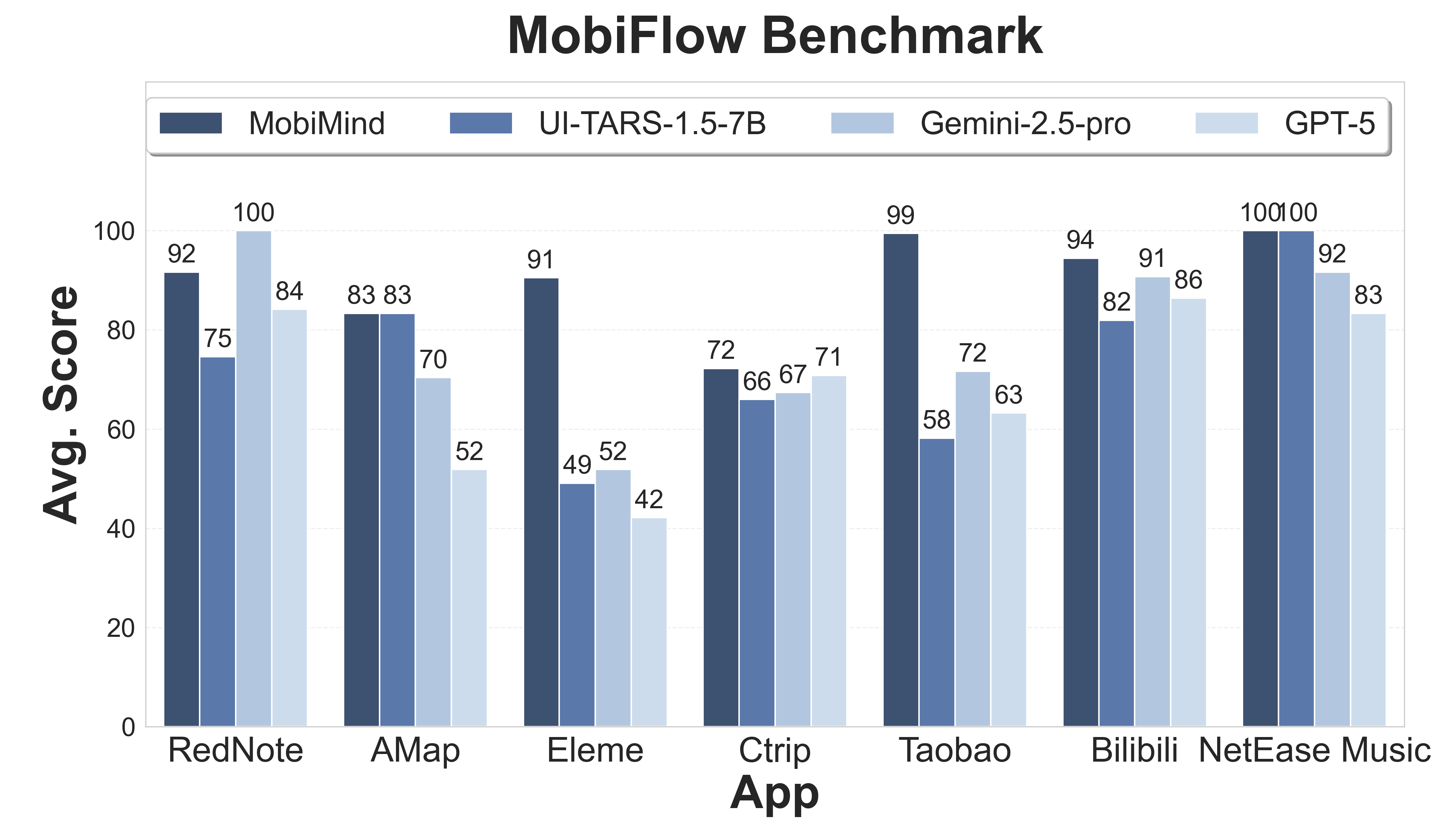 |
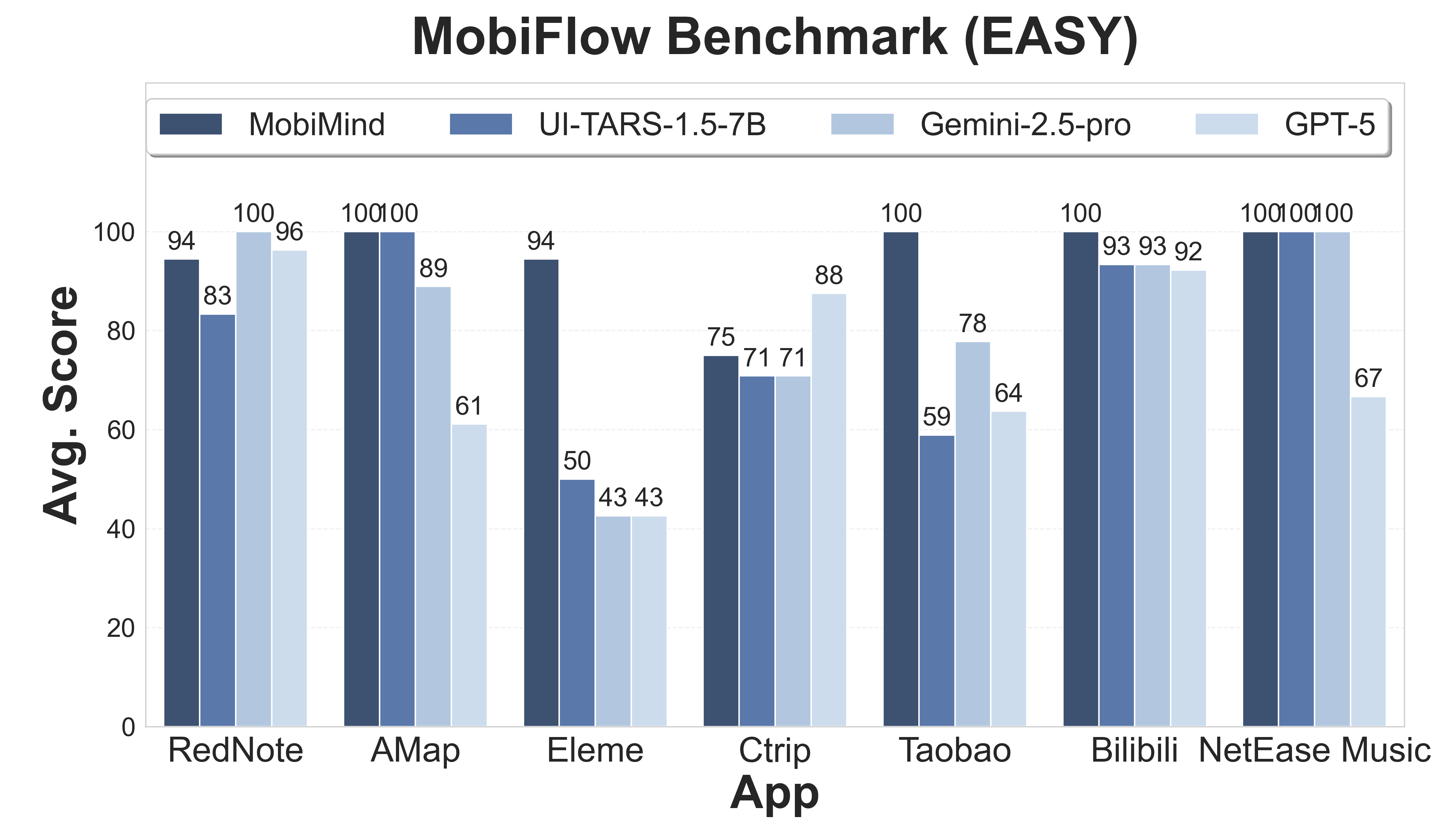 |
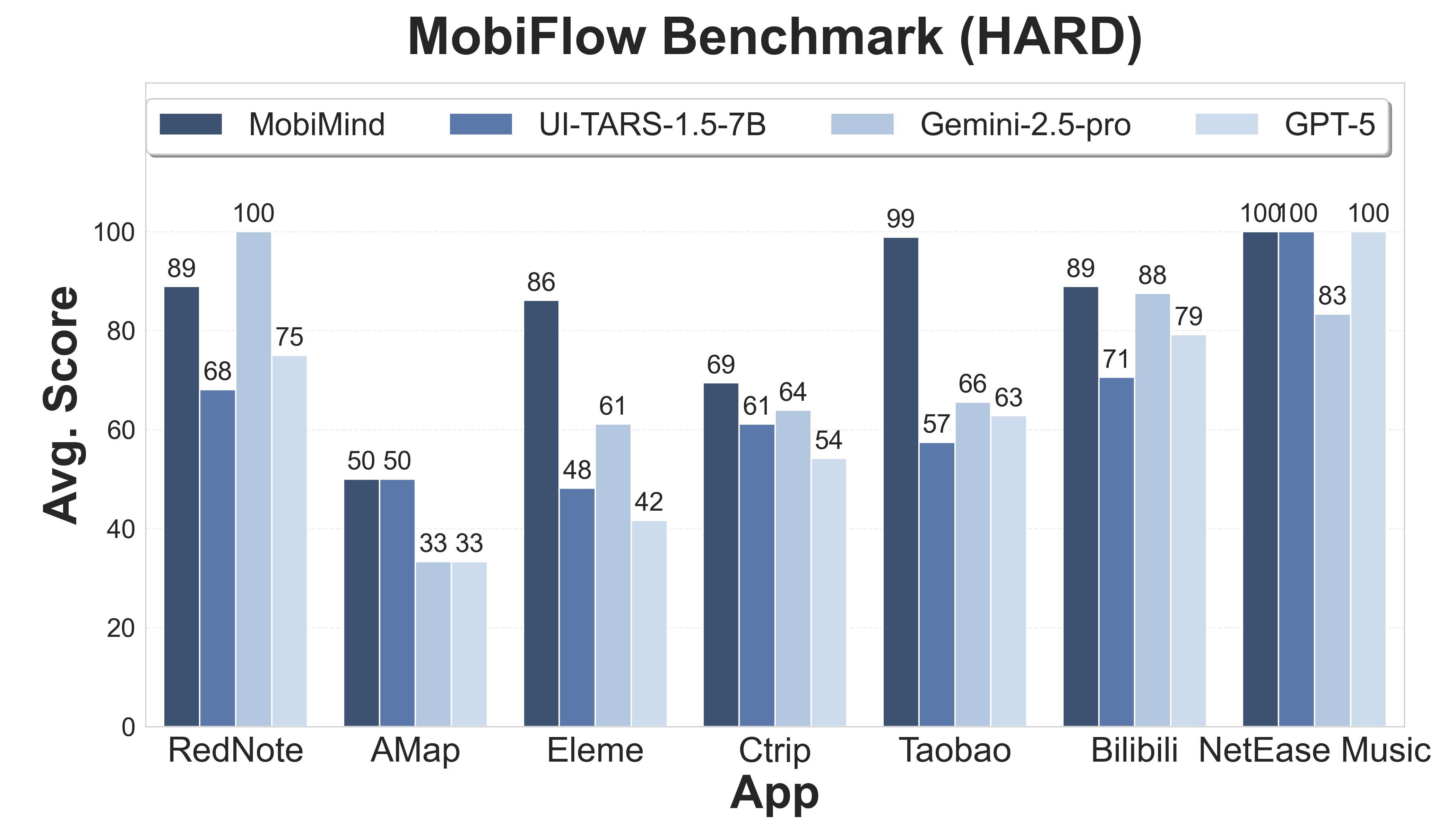 |
Deploy model inference service with vLLM:
vllm serve IPADS-SAI/MobiMind-Decider-7B
For more usage details, e.g., execute GUI tasks with ADB or our Android App, please refer to our repo!