
This is the most underreported model when it comes to agentic coding and intelligence

I am running a reap version of the same and still step 3.5 flash does really excel even compared to qwen series and minimax reap for my agentic coding in rust. Hope this team continues its good work., best of luck!!
Minimax (non-reaped) seems better to me, even at IQ2. M2.7 will wipe the floor with Step-3.5-Flash, so looking forward to Step-3.6-Flash.
Otherwise, absolutely; probably still better than Qwen3.5 122B, for example. Though a large part of the problem was that inference engines like llama.cpp and vllm couldn't run them for a long time, I think. Arguably that's the same issue: they were underappreciated.

{kind=link}
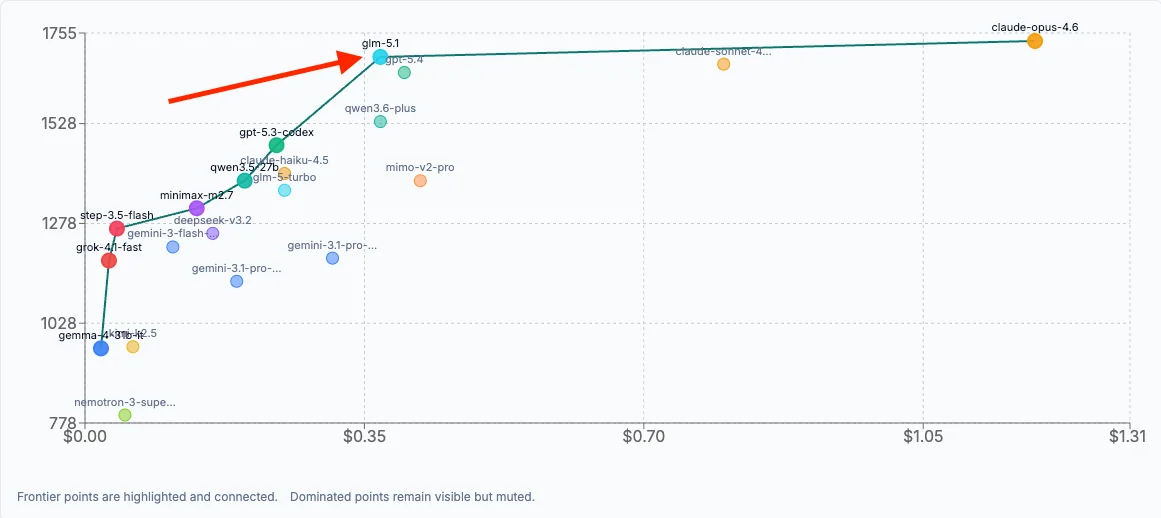
https://x0.at/vURT.webp comparison to SOTA models. Very very strong performance!
Not sure what that's measuring, but dollars isn't really a useful comparison for open weight models. Need the agentic intelligence per token, really. On https://artificialanalysis.ai , the "Agentic Index" and "Intelligence vs. Output Tokens" charts are useful:
As you can see there, Step-3.5-Flash WAS good for an older model, but needs an update. MiniMax M2.7 currently outclasses it. MiniMax and StepFun have been collaborating though, and that's part of the reason for M2.7 being ahead, so we'll see what 3.6 is like.
One more thing to add is that StepFun are targeting 128GB machines with Flash: 128GB VRam (4x32GB GPUs, or 1xMac with 128GB unified RAM), so that's achievable for a lot of the huggingface/local llama crowd, and with a more aggressive quant, it's in reach for 96GB folks too. MiniMax will run in 96GB, but it's a tighter squeeze and a very aggressive quant.