
SeeThrough3D: Occlusion Aware 3D Control in Text-to-Image Generation
Paper
• 2602.23359 • Published
• 1
![]()
![]()
![]()

We recommend creating a conda environment named st3d with Python 3.11:
conda create -n st3d python=3.11
conda activate st3d
Install the dependencies using the provided requirements.txt, then install the project itself in editable mode:
pip install -r requirements.txt
pip install -e .
Inference of this model requires ~38 GB VRAM on the GPU. Note that the inference runs Blender in EEVEE mode, which runs faster on workstation GPUs like the NVIDIA RTX A6000, compared to data center GPUs like the NVIDIA H100.
We use FLUX.1-dev as the base model. To download the SeeThrough3D LoRA checkpoint,
conda activate st3d
python3 download_checkpoint.py

It is best to perform inference using the 🤗 Gradio interface, which makes it easy to specify 3D layouts. To launch the interface, run
cd inference
conda activate st3d
python3 app.py
For a detailed guide on how to use the Gradio interface, please refer to the wiki.
The created 3D layouts can be saved by clicking the 💾 Save Scene button. This functionality stores the 3D layout along with other information such as seed, image size, prompt, etc. in a pickle file. We also provide various example layouts under the 🖼️ Examples section.
The interface requires some available ports on the host machine, these can be configured in inference/config.py.
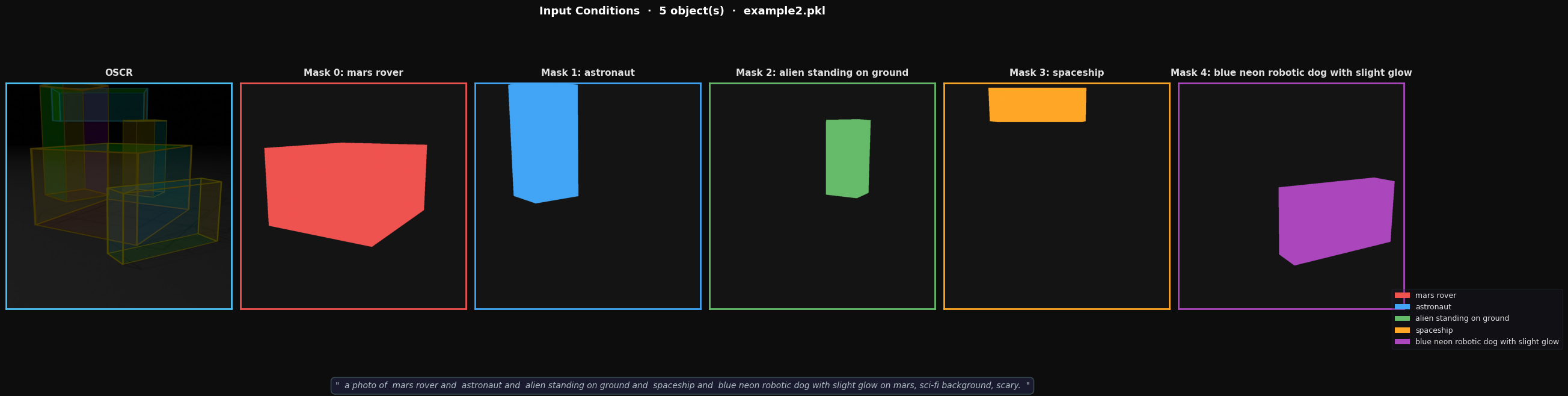
The inference notebook is located at infer.ipynb. It is able to load a scene saved by the 🤗 Gradio interface (described above), visualize the inputs to the model (shown below), and perform inference. The inference notebook also requires some available ports on the host machine, these can be configured in inference/config.py.
By default, the data is downloaded in the dataset directory. To change the download location, edit the LOCAL_DIR variable in dataset/download.py.
cd dataset
conda activate st3d
./setup_data.sh
We are working on making the data compatible with 🤗 datasets library for ease of visualization and streaming, see va1bhavagrawa1/seethrough3d-data
Edit train/train.sh to specify the downloaded dataset path.
We train the model for a single epoch at resolution 512, effective batch size of 2 (~25K steps). This requires 2x 80 GB GPUs (one image per GPU).
cd train
# edit the default_config.yaml to specify GPU configuration
conda activate st3d
./train.sh
The training takes ~6 hours on 2x NVIDIA H100 GPUs.
We further do an optional second stage finetuning (~5K steps) at resolution 1024, which improves control and realism during inference. The number of finetuning steps for this stage can be controlled by setting the flag --stage2_steps. This stage requires 2x 96 GB GPUs.
The training VRAM requirement can be reduced to 2x 48 GB GPUs (for the first stage) by caching text embeddings. To cache the text embeddings, run the following.
cd train/caching
# change `DATASET_JSONL` global var in `train/caching/cache.py` to point to training dataset jsonl
conda activate st3d
./cache_text_embeddings.sh
Now, set the flag --inference_embeds_dir in train/train.sh to the location of the cached text embeddings.
Note: The VRAM requirements can be further reduced using training time optimizations such as gradient checkpointing. We plan to implement this in the future. We are also welcome to any PRs regarding this.
If you find this work useful please cite:
@misc{agrawal2026seethrough3docclusionaware3d,
title={SeeThrough3D: Occlusion Aware 3D Control in Text-to-Image Generation},
author={Vaibhav Agrawal and Rishubh Parihar and Pradhaan Bhat and Ravi Kiran Sarvadevabhatla and R. Venkatesh Babu},
year={2026},
eprint={2602.23359},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2602.23359},
}